
Understanding Sentiment Analysis and Transformers
Sentiment analysis, a subfield of natural language processing (NLP), focuses on determining the sentiment or opinion expressed in a piece of text. Transformers, powered by self-attention mechanisms, assign varying importance to different words, allowing them to effectively understand context. This makes them highly efficient for classifying text into positive, negative, or neutral sentiments based on underlying polarity.
Dataset and Task Overview
For this project, we utilize the tweet_eval dataset, a well-established benchmark for Twitter sentiment classification. The dataset consists of tweets labeled as positive, negative, or neutral, offering a diverse mix of real-world social media sentiments.
Project Tasks:
✅ Load the tweet_eval dataset using the Hugging Face library.
✅ Explore dataset configurations, splits, and features.
✅ Preprocess text data, including tokenization, truncation/padding, conversion to tensor format, and cleaning usernames.
✅ Split the dataset into training and testing sets.
✅ Train and evaluate the model for performance and accuracy.
✅ Save the trained model.
✅ Deploy the model in a Flask web application for real-world usage.
Algorithm and Implementation
Our implementation leverages PyTorch and the Hugging Face Transformers library. Key components include:
1️⃣ Data Preprocessing
Text data undergoes preprocessing with the DatasetToTensor class, handling:
- Tokenization
- Truncation/Padding
- Conversion to tensor format
2️⃣ Model Implementation
We employ the SentimentAnalysis class, which utilizes the cardiffnlp/twitter-roberta-base-sentiment-latest pre-trained transformer model for sequence classification.
3️⃣ Training and Evaluation
Defined training and evaluation loops handle:
- Model training
- Performance evaluation
- Accuracy and loss calculation
Enhancements for Performance Optimization
To improve sentiment analysis accuracy, multiple techniques were implemented:
✅ Fine-Tuning: Pre-trained transformer models were fine-tuned on the tweet_eval dataset for sentiment analysis.
✅ Hyperparameter Tuning: Adjustments to parameters like learning rate and batch size enhanced model efficiency.
✅ Model Selection: Multiple pre-trained transformers were evaluated to identify the best-performing one.
Custom Model Performance
📊 Training Loss: 1.31
📊 Test Loss: 0.74
📊 Test Accuracy: 71.88%
Deploying the Model with Flask
To make sentiment analysis accessible, we built a Flask web application that takes text input and provides sentiment scores.rom a text field
🖥️ Web Application Features
🏠 Home Page – Users enter text and receive sentiment classification.
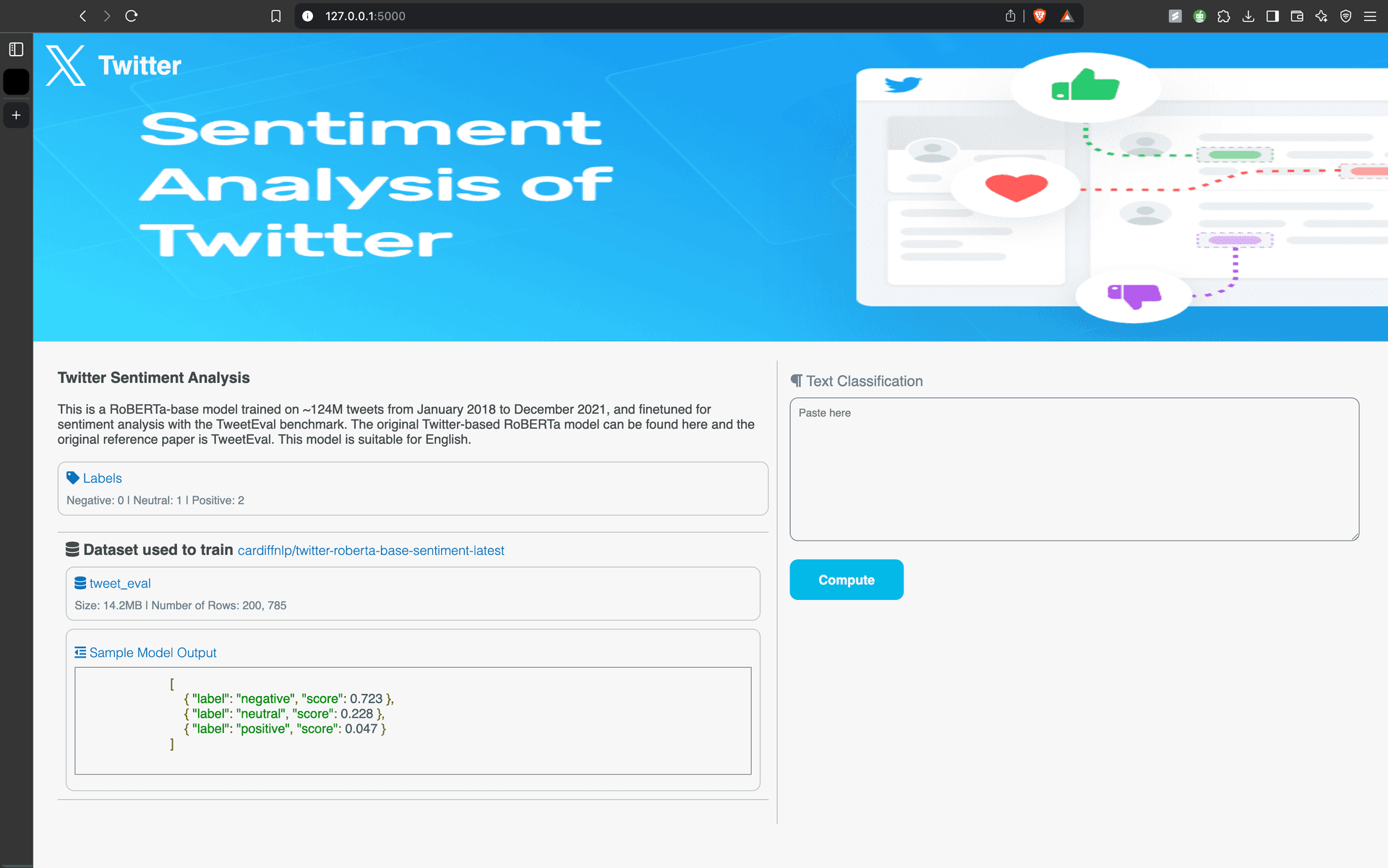
📡 Server Code – Handles model loading and API requests.
1from flask import Flask, render_template, request
2import torch
3from transformers import RobertaForSequenceClassification, RobertaTokenizer
4
5from utils.utils import SentimentAnalysis, SentimentAnalysisModel
6
7app = Flask(__name__)
8PORT = 5000
9
10device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
11model_name = "cardiffnlp/twitter-roberta-base-sentiment-latest"
12classifier = RobertaForSequenceClassification
13tokenizer = RobertaTokenizer
14
15SentimentAnalysis(model_name, tokenizer, classifier, num_labels=3, device=device)
16
17
18@app.route('/', methods=['GET', 'POST'])
19def index():
20 input_text = ''
21 outputs = []
22 if request.method == 'POST':
23 input_text = request.form['input_text']
24 model = SentimentAnalysisModel([input_text])
25 outputs = [r for r in model][0]
26 return render_template('index.html', input_text=input_text, outputs=outputs)
27
28if __name__ == '__main__':
29 app.run(debug=True)📂 File Structure – Organizes code efficiently.
1# Project Structure
2
3```
4/app
5│── /static # Static assets (images, fonts, etc.)
6│── /templates # HTML templates
7│── /utils # Model
8│── app.py # Main source code
9│── .env # Environment variables
10│── .gitignore # Ignored files in Git
11│── README.md # Project documentation
12│── requirements.txt # Project required packages
13```🎨 HTML Layout – Provides an interactive frontend for user input.
1 <div class="container">
2 <div class="header">
3 <div class="logo-container">
4 <img class="logo" src="{{ url_for('static', filename='logo.webp')}}" alt="logo" />
5 <h2 class="logo-title">Twitter</h2>
6 </div>
7 <img class="banner" src="{{ url_for('static', filename='banner.png')}}" alt="banner" />
8 </div>
9 <div class="main-content">
10 <div class="about">
11 <h3>Twitter Sentiment Analysis</h3>
12 <br />
13 <p>This is a RoBERTa-base model trained on ~124M tweets from January 2018 to December 2021, and finetuned for sentiment
14 analysis with the TweetEval benchmark. The original Twitter-based RoBERTa model can be found here and the original
15 reference paper is TweetEval. This model is suitable for English.</p>
16 <br />
17
18 <div class="labels">
19 <a><i class="fas fa-tag"></i> Labels</a>
20 <br />
21 <p>Negative: 0 | Neutral: 1 | Positive: 2</p>
22 </div>
23 <div class="model-info">
24 <h3><i class="fas fa-database"></i> Dataset used to train <a href ="https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest?text=Covid+cases+are+increasing+fast%21">cardiffnlp/twitter-roberta-base-sentiment-latest</a></h3>
25 <div class="dataset">
26 <a href="https://huggingface.co/datasets/tweet_eval"> <i class="fas fa-database"></i> tweet_eval</a>
27 <br />
28 <p>Size: 14.2MB | Number of Rows: 200, 785</p>
29 </div>
30 <div class="output">
31 <a><i class="fas fa-outdent"></i> Sample Model Output</a>
32 <pre class="prettyprint lang-json" style="padding: 10px;">
33 [
34 { "label": "negative", "score": 0.723 },
35 { "label": "neutral", "score": 0.228 },
36 { "label": "positive", "score": 0.047 }
37 ]
38 </pre>
39 </div>
40 </div>
41 </div>
42 <div class="computation">
43 <form class="search-form" action="" method="post">
44 <div class="input-text">
45 <label for="tweet-text"><i class="fas fa-paragraph"></i> Text Classification</label>
46 <textarea class="textarea" placeholder="Paste here" rows="10" name="input_text">{{ input_text }}</textarea>
47 </div>
48 <input type="submit" value="Compute">
49 </form>
50 <div class="output {% if input_text == '' %}{{ 'hidden' }}{% else %} '' {% endif %}">
51 {% for output in outputs %}
52 <div class="scores">
53 <div class="progress-bar" style="width: calc({{output.score}} * 100%)"></div>
54 <div class="result">
55 <p class="label"> <i class="fa-solid fa-square-poll-horizontal"></i> {{ output.label }}</p>
56 <p class="score">{{ output.score }}</p>
57 </div>
58 </div>
59 {% endfor %}
60 </div>
61 </div>
62 </div>
63 </div>
64Final Thoughts
With a robust transformer-based sentiment analysis model, we achieved 71.88% accuracy on real-world Twitter data. As we refine the approach with additional data and hyperparameter tuning, accuracy can further improve. Deploying the model in a Flask app makes sentiment analysis accessible for real-time applications. 🚀